Welcome! Here you will find my latest projects
Investigating Parody from Social Media Accounts
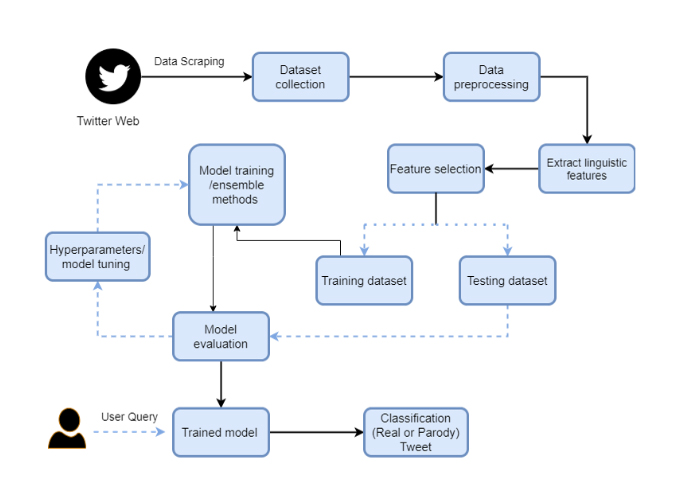
Parody is a widespread comic on different social media platforms. As the usage of social media increases, the number of parody accounts increases as well. The main purpose of parody accounts is to spread fake news or to criticize someone in comic ways. In this paper, we investigate parody for different social media accounts. For this study, a customized tweets dataset is created related to different Pakistani personalities and companies. The experiment is carried out using different machine learning and deep learning methods. Our results indicate an accuracy of 92% using RoBERTa. Paper Accepted in IEEE-SEEDA-CECNSM 2021
Predicting Fake News using GloVe and BERT Embeddings
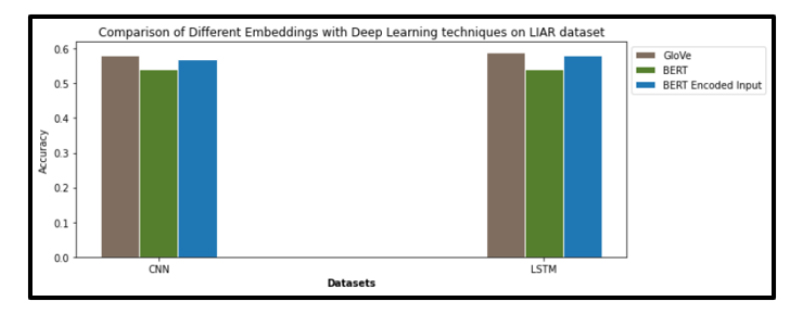
The focus of this research is to identify fake news by applying different artificial intelligence techniques along with different embeddings and to assess the performance of all the applied models. The performance of these models and the embeddings is compared based on precision, accuracy, F1-score and recall. For machine learning techniques SVM, KNN, Naive Bayes, Logistic Regression and Decision Trees are used, while for deep learning techniques CNN and LSTM are used with GloVe and BERT embeddings. Multiple experiments using these techniques are performed on the LIAR and Fake-or-Real dataset.Naive Bayes has shown the best results from machine learning techniques on both datasets. While in deep learning techniques, LSTM with GloVe has shown the best results on the LIAR dataset and CNN with BERT has shown the best performance on the Fake-or-Real dataset. Overall GloVe word embeddings performed well on the LIAR dataset while BERT sentence embeddings have shown good performance on the Fake-or-Real dataset. Paper Accepted in IEEE-SEEDA-CECNSM 2021
Building Multi-Label Text Classifiers for arXiv Paper Abstract Dataset
Paper submission systems (CMT, OpenReview, etc.) require the users to upload their paper titles and paper abstracts and then specify the subject areas their papers best belong to. arXiv is a free distribution service and an open-access archive for 1,950,165 scholarly articles in the fields of physics, mathematics, computer science, quantitative biology, quantitative finance, statistics, electrical engineering and systems science, and economics. It is mostly used for academicians to upload their papers. The Kaggle arXiv Paper Abstract Dataset provides more than 38000 unique paper titles along with their summaries and subject areas. It would be interesting if submission systems like arXiv provide viable subject area suggestions as to where the corresponding papers could be best associated with? Our task is to build a text classifier model that can predict the subject areas given paper abstracts and titles. Please visit the Blog that explains the project.

Classifying Pet Breeds
Just few years ago, Pet Breeds classification problem was considered challenging task. However, today it has become too easy! Thanks to the fastai and other such libraries. For the complete code, please visit the Blog that explains the project and the key concept of learning rate finder.

Topic Modeling
To practically perform the task we will be using the 20Newsgroups dataset from the sklearn library. We will be using SVD and NMF for our experimentation as there are other great resources for LDA and PLSA. please visit the Blog that explains the project and the dataset.

Training a Digit Classifier using fast.ai
Pixels are the foundation of computer vision and the MNIST dataset is used as a hello world program for image recognition problems. The MNIST dataset contains images of handwritten digits collected by National Institute of Standards and Technology. Almost every deep learning library has this dataset as part of their toy datasets. The fastai also provides samples of MNIST dataset. Lets try our hands on the MNIST_SAMPLE provided by fastai to create a model that classifies 3 or a 7. please visit the Blog that explains the project and the dataset.

Rock-Paper-Scissors Image Classification using fastai
Rock Paper Scissors Dataset is a multi class dataset for learning computer vision. The Rock-Paper-Scissors dataset contains 2,892 images of diverse hands in Rock/Paper/Scissors poses. please visit the Blog that explains the project and the dataset.

Follow and Support
For more interesting content, follow my Blog.